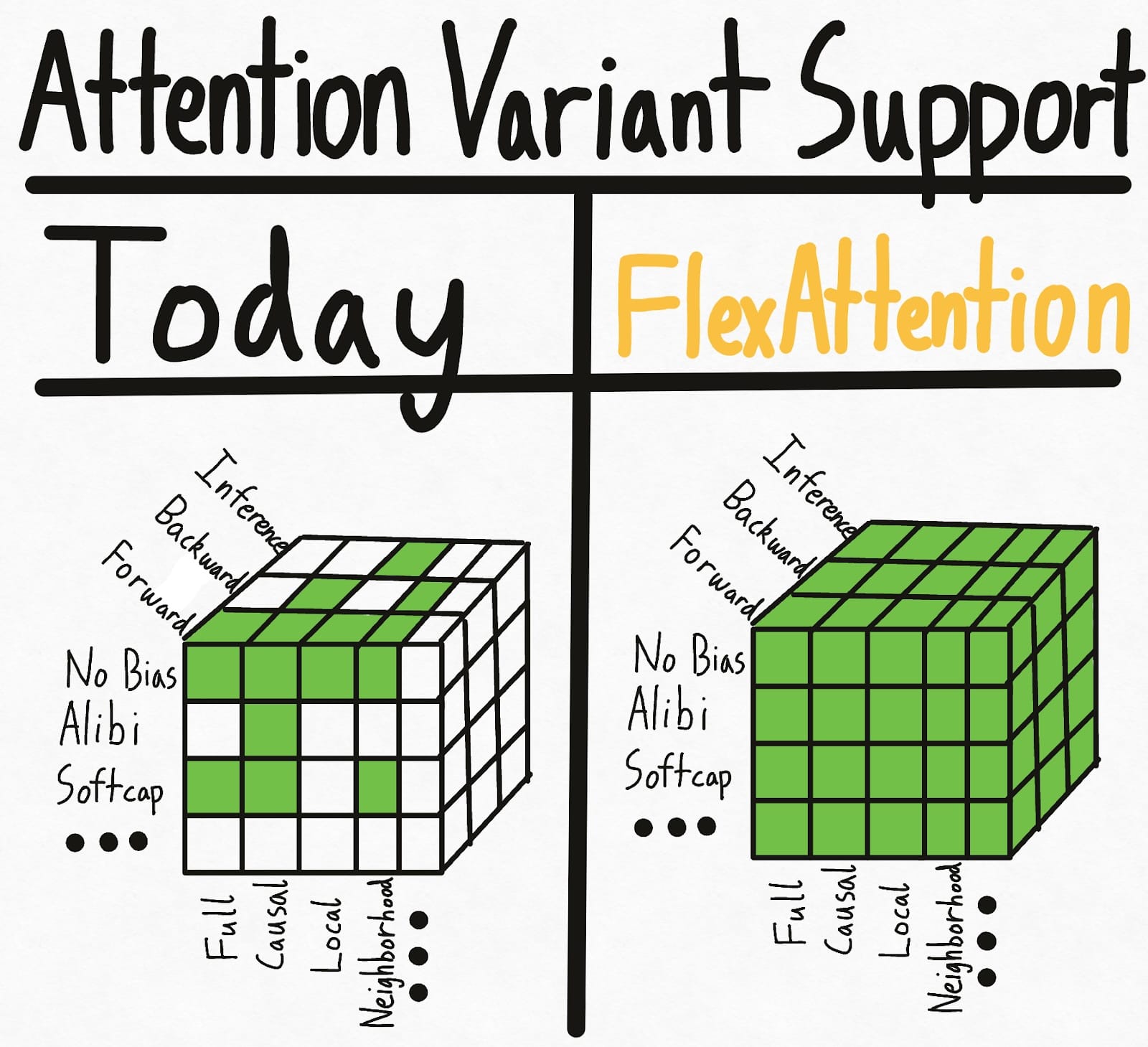
The Flexibility of PyTorch with the Performance of FlashAttention
Using FlexAttention for inference: backend optimized for decoding and PagedAttention.

A High-Level DSL (PyTorch with Tiles) for Performant and Portable ML Kernels
AMD Collaboration with the University of Michigan offers High Performance Open-Source Solutions to the Bioinformatics Community